
The Open-Book Exam: A Deep Dive into RAG and the AI Knowledge Revolution
Part 2 of the "Beyond the Window" Series. We discuss all things about successful RAG implementations, understand the pitfalls and also understand the evolution from RAG to Agentic RAG to MCP.


In our last chat, we met the modern AI: an Elephant with a colossal memory. We marveled at its ability to recall entire books (its massive context window), but we also discovered its Achilles' heel: "context rot." Even with a perfect memory, it can get overwhelmed and lose track of key facts buried in the "muddy middle" of its thoughts.
This presents a huge problem. What good is a brilliant expert if they can't reliably recall the most important details when you need them? Furthermore, this brilliant Elephant has only read the public internet. It hasn't read your company's internal reports, your project's documentation, or your customer support history.

You can't just stuff all that private information into its context window every time, that’s inefficient and risks the dreaded brain fog. So, how do you give your AI expert a perfect, just-in-time briefing on your private world without overwhelming it?
You don't give it a bigger brain. You hire it a personal librarian.
This librarian is a system known as Retrieval-Augmented Generation, or RAG, and it’s the single most important architecture in applied AI today. It’s what makes AI practical for real-world business.
What in the World is RAG?
Let’s stick with our librarian analogy.
An off-the-shelf Large Language Model (like Gemini or GPT-4) is like a world-renowned genius professor. They can write poetry, explain quantum physics, and philosophize about the meaning of life. But if you ask them, "What were our company's Q3 sales figures in the EMEA region?" they will stare at you blankly. They were never given that book to read.
Retrieval-Augmented Generation (RAG) is the hyper-efficient librarian you hire to work with this professor.
When you ask the professor your question, the RAG librarian silently and instantly springs into action. It zips back into your company's private library, finds the exact quarterly report, opens it to the precise page with the EMEA sales figures, and places that single, relevant page right in front of the professor.
Now, the professor glances down, sees the specific data, and answers you with confidence: "According to the Q3 report, sales in the EMEA region were $4.2 million, primarily driven by strong performance in Germany."
The professor seems like an expert on your business, but their genius was augmented by the librarian's perfect, timely retrieval. That’s RAG in a nutshell: Retrieval (finding the right info) + Generation (using that info to create a great answer).
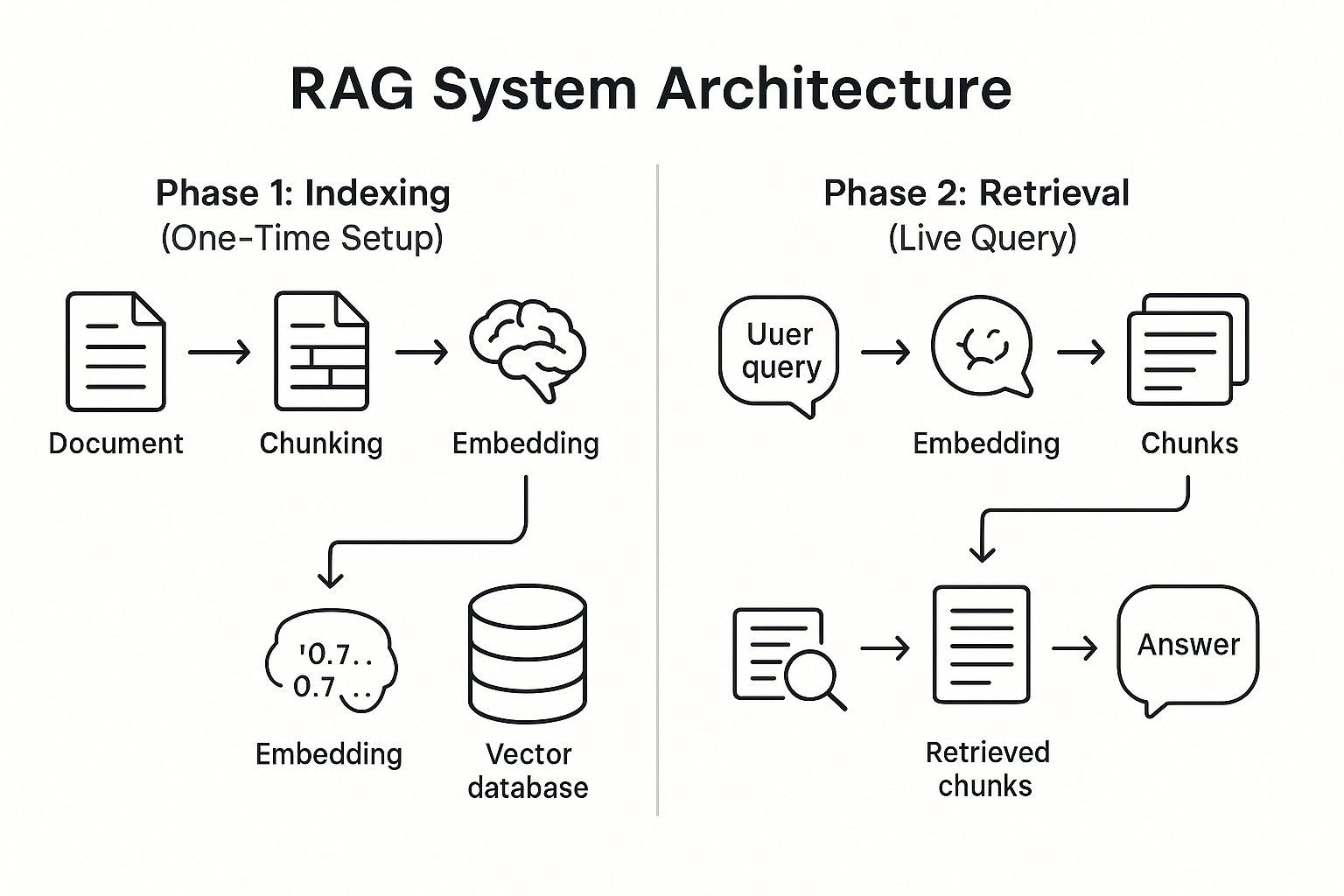
The Architecture: How the AI's Library Works
This librarian doesn't just magically appear; it relies on a clever two-phase system.
Phase 1: Building the Special Library (Indexing)
This is the prep work that happens before you ever ask a question. You take all of your proprietary documents—product manuals, PDFs, transcripts, knowledge bases—and hand them to the librarian to organize.
Chunking: First, the documents are broken down into smaller, manageable chunks. Think of it as tearing a book into individual, meaningful paragraphs.
Embedding: Next, a special AI model called an "embedding model" reads each chunk and converts its semantic meaning into a string of numbers, called a vector. This is the magic step. The vector is like a highly sophisticated GPS coordinate for meaning. Chunks with similar meanings will have similar coordinates.
Indexing: These vectors are then stored in a specialized database called a vector database. This isn't like a normal database that just stores text; it's a library organized by meaning itself. Think of it as the ultimate Dewey Decimal System, where books on similar topics are physically next to each other.
Phase 2: Answering Your Question (Retrieval & Generation)
This is what happens in real-time when you interact with the AI.
Query: You ask your question: "Why are customers complaining about our return policy?"
Retrieve: The RAG librarian takes your question, converts it into a vector, and then searches the vector database for the text chunks with the most similar vector coordinates. It finds customer support tickets, internal memos about policy changes, and help articles—all related to "returns." It grabs the top 5 most relevant chunks.
Augment: This is the core of the "Augmented" part. The system creates a new, temporary prompt for the LLM. It looks something like this:
Background Information: [Chunk from support ticket 1] [Chunk from internal memo] [Chunk from help article]User's Question: Why are customers complaining about our return policy?
Answer based ONLY on the information aboveGenerate: The LLM receives this perfectly prepped briefing. It never sees your entire library, only the handful of highly relevant snippets. It then uses its brilliant reasoning skills to synthesize those snippets into a coherent, factual, and helpful answer.
The Smart Alternative: Why RAG Often Beats Fine-Tuning
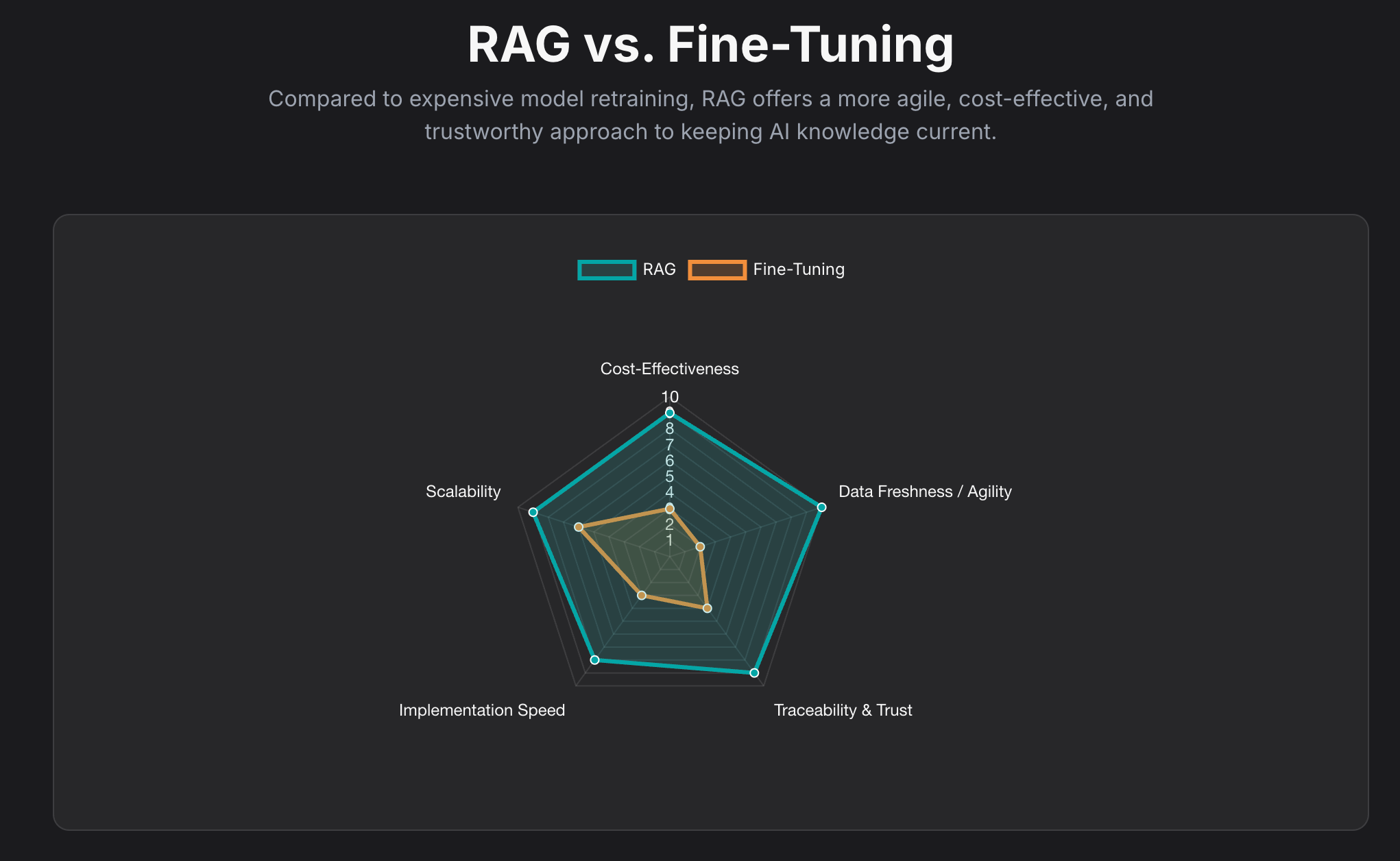
To keep an LLM's knowledge current, one could theoretically retrain or "fine-tune" the model on new data. However, for many enterprise use cases, RAG presents a more agile, efficient, and cost-effective strategy.
Cost-Effectiveness: Retraining a foundation model is a computationally intensive and financially demanding process. RAG sidesteps this entirely. Updating the system's knowledge requires only updating the external documents in the knowledge library, a process that is orders of magnitude cheaper and faster.1
Data Freshness and Agility: RAG systems can be connected to real-time data streams, from news feeds to internal databases. This ensures the LLM's responses are always based on the most current information available, without the lag time required for model retraining.
Traceability and Trust: Fine-tuning bakes new knowledge into the model's parameters, but it doesn't inherently solve the "black box" problem. It's still difficult to know precisely why the model gave a certain answer. RAG's ability to cite its sources provides a clear audit trail, drastically reducing the risk of hallucinations and fostering user trust.
This approach aligns AI with a more practical and powerful form of intelligence. Human experts are not valued for their ability to memorize encyclopedias (a "closed-book" skill) but for their ability to find, synthesize, and apply relevant information to solve novel problems (an "open-book" skill).
By equipping LLMs with this capability, RAG represents a pivotal step toward creating AI that works not as an opaque oracle, but as a transparent and capable partner in knowledge work.
Why It Matters: The Compelling ROI of Instant Expertise
While the technology behind RAG is fascinating, business leaders and investors rightly ask a more pragmatic question: "What is the return on investment?" The answer is not merely incremental. Organizations that strategically implement RAG are reporting transformative returns, with some seeing a 300-500% ROI within the first year alone.
This remarkable financial impact stems from RAG's ability to solve some of the most persistent and costly inefficiencies in modern knowledge work. It moves beyond being a technological novelty to become a powerful engine for productivity, innovation, and risk mitigation.
Let's dissect the five core value drivers that constitute the compelling business case for RAG.
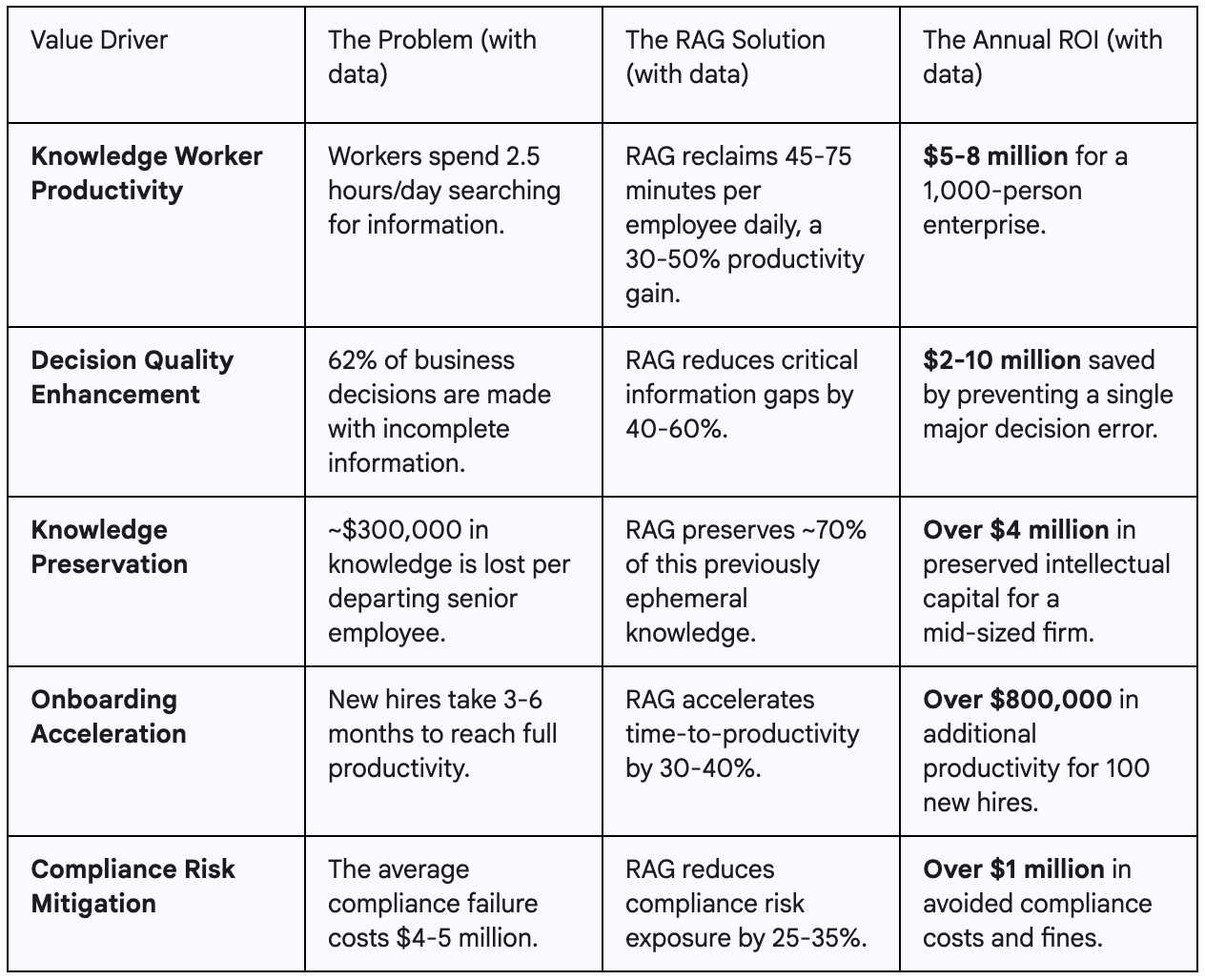
While these metrics are powerful in isolation, their true impact is compounded. Better-informed workers make higher-quality decisions. Faster onboarding creates a more productive workforce sooner. Preserved knowledge prevents teams from re-solving old problems.
This creates a virtuous cycle where the entire organization's capacity for innovation and execution reaches unprecedented levels. The most successful RAG implementations are therefore viewed not as defensive cost-saving measures, but as offensive strategic investments that unlock new revenue streams and build a lasting competitive advantage.
RAG in the Wild: Real-World Use Cases
RAG isn't a theoretical concept; it’s the engine behind thousands of real AI applications today. In knowledge-intensive fields where accuracy, currency, and context are non-negotiable, RAG acts as an expert co-pilot, augmenting the capabilities of human professionals.
From our point of view, we are seeing four major themes emerge with use cases for RAG
The Corporate Brain: Powering the Intelligent Enterprise: In the enterprise scenario, organizational data is siloed across applications and knowledge sources. Transforming & unifying the information into conversational intelligence that allows any employee to query information is a big use case.
The Expert Co-Pilot: Augmenting High-Stakes Professions: In knowledge-intensive fields where accuracy, currency, and context are non-negotiable, RAG acts as an expert co-pilot, augmenting the capabilities of human professionals. These include Healthcare, Legal & Finance use-cases adoption with AI.
The Digital Marketplace: The End of Generic Customer Experiences: RAG is finally able to deliver on the promise of true personalization in e-commerce and retail. For most people, they have moved beyond a Google Search of products to more in-depth analysis of reviews and availability of products on AI providers like Google Gemini or ChatGPT.
The Modern Creator: From Code to Content: From code generation to journalism, today every creator is adopting AI to become faster & do more. AI is also acting as a tutor either implicitly or explicitly to end consumer and this becomes a great area to explore RAG
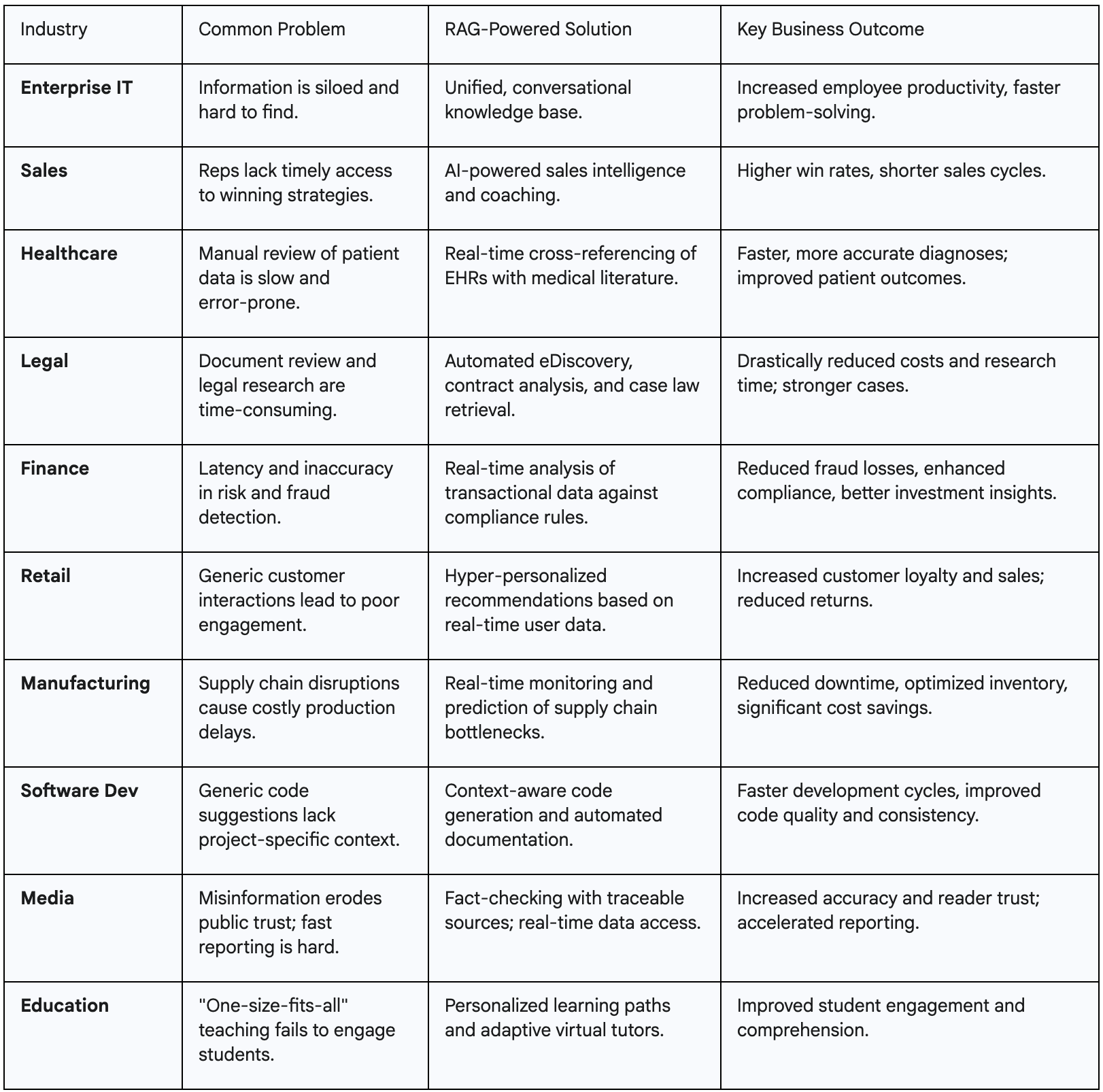
Across all these applications, a central theme emerges: RAG's primary function is to close the "context gap." Every use case, from a doctor diagnosing a patient to a developer writing code, involves a general-purpose intelligence (the LLM or the human) that requires specific, timely, and correct context to make an optimal decision.
RAG's purpose is to inject that context precisely when and where it's needed. This implies that the competitive advantage in the age of generative AI will be defined less by the model one uses, and more by the quality, structure, and accessibility of the proprietary knowledge base one can connect it to.
Evolution and the Road Ahead
Basic RAG, as described, is already powerful, but the field is evolving at a breakneck pace. The librarian is getting smarter.
Advanced RAG systems no longer just retrieve and generate. They might first decompose a complex user question into several sub-questions. Then, they decide which documents to search for each sub-question. Finally, they synthesize the multiple search results into a comprehensive answer.
Achieving high-quality results from a RAG system requires moving beyond a naive implementation. It involves a series of advanced techniques that can be thought of as tuning a high-performance car engine—optimizing the fuel intake (ingestion), the search algorithm (retrieval), and the onboard computer (reasoning) for peak performance.
Agentic RAG (The Onboard Computer)
Some questions are too complex to be answered by a single retrieval step. For example, a query like "Compare the market share of our top three competitors in Europe versus Asia." A basic RAG system would struggle. This is where Agentic RAG comes in.
An "agent" is an LLM-powered system that can reason, plan, and execute a sequence of actions to achieve a goal. Agentic RAG breaks a complex query down into a series of smaller, manageable sub-queries. For the example above, the agent might:
Sub-query 1: "What is Competitor A's market share in Europe?" -> Retrieve -> Store result.
Sub-query 2: "What is Competitor A's market share in Asia?" -> Retrieve -> Store result.
Repeat for Competitors B and C.
Synthesize: Pass all the retrieved results to the LLM with a final prompt: "Based on these data points, generate a comparison of the market share for these competitors in Europe versus Asia."
This approach, also known as multi-hop reasoning, transforms RAG from a linear pipeline into a dynamic, multi-step reasoning process, capable of tackling far more complex analytical tasks.
The Multimodal Leap: When RAG Gets Eyes & Ears
The vast majority of the world's information is not plain text. It is locked in images, charts, tables, audio files, and videos and unlocking this frontier unlocks a new dimension in bringing in context to LLMs.
Multimodal RAG is the next frontier, extending the system's senses beyond the written word to understand and reason over this rich, diverse data. There are three primary approaches to building these systems:
Unified Embedding Space: This method uses a powerful multimodal embedding model, like OpenAI's CLIP, to convert different data types (e.g., images and text) into a shared vector space. In this space, the vector for a picture of a golden retriever is located very close to the vector for the text "a photo of a golden retriever." This allows for seamless cross-modal search—using an image to find relevant text, or using text to find relevant images.
Grounding in Text: This approach uses a vision-capable LLM (like GPT-4o or LLaVA) to first generate detailed text descriptions or summaries of non-text content. For example, it might describe an image ("A bar chart showing a 30% increase in Q3 sales") or summarize a table. The RAG system then performs its retrieval on this generated text, effectively grounding all modalities in a common language.
Separate Stores + Reranking: This strategy maintains separate, specialized vector stores for each modality (one for text, one for images, etc.). A user query is run against all stores in parallel. A dedicated multimodal reranking model then assesses the combined results from all stores to identify the most relevant pieces of information, regardless of their original format.
The Context Revolution: Multi-Context Processing (MCP) Arrives
This is the bleeding edge of AI reasoning. If Agentic RAG is like a diligent researcher tackling a problem one step at a time, Multi-Context Processing (MCP) is like convening a panel of diverse experts to debate a topic and synthesize their perspectives simultaneously.
MCP is defined as the capability of a language model to simultaneously analyze, integrate, and synthesize information from multiple, distinct sources or contexts within a single inference cycle.
The key distinction is between sequential and parallel processing:
Agentic RAG / Prompt Chaining is sequential. It performs one retrieval, generates an intermediary thought or result, and uses that output as the input for the next step.
Multi-Context Processing is parallel. It can take in multiple, independent streams of information at the same time—for example, a legal document, a financial spreadsheet, and a real-time news feed—and reason across them holistically.
This is a monumental leap. It enables a far more nuanced and sophisticated form of reasoning. An MCP-enabled system could, for instance, analyze a company's quarterly earnings report (structured data), the CEO's comments on the earnings call (unstructured text), and the real-time stock market reaction (time-series data) to generate a comprehensive risk and opportunity analysis. It moves the AI's capability beyond simple fact retrieval and into the realm of perspective synthesis, a critical step toward more robust, human-like understanding.
The evolution of RAG mirrors the maturation of human research methodologies. Basic RAG is like looking up a fact in an encyclopedia. Advanced retrieval is like being a skilled librarian. Agentic RAG is like a researcher following a trail of citations from one paper to the next. And MCP is like a panel discussion, where experts from different fields synthesize their knowledge to form a novel conclusion. We are not just teaching the AI what to know; we are teaching it how to learn.
Navigating the Pitfalls: A Pragmatist’s Guide to RAG Implementation
One of my favorite quotes ever is
There are no silver bullets, only lots of lead bullets to fix a problem - Ben Horowitz
If you have not read the article, I would highly recommend - Link to article
The reason I referenced the above article is that RAG is not a silver bullet. There are pitfalls in leveraging RAG and we want to bring the other perspective as well.
For all its transformative potential, RAG is not a magical solution that works perfectly out of the box. Real-world applications quickly expose its limitations, and a "field of dreams" approach—"if you build it, they will come"—is a recipe for disappointment. Successful implementation requires a pragmatic understanding of the common pitfalls and a strategic approach to navigating them. Ignoring these challenges can lead to systems that are unreliable, inaccurate, and ultimately, untrustworthy.
Challenge 1: The "Garbage-In, Garbage-Out" Syndrome
This is the most fundamental rule of any data system, and it applies with a vengeance to RAG. The quality of a RAG system's output is absolutely capped by the quality of its knowledge base. If the source documents fed into the system are inaccurate, poorly formatted, outdated, or contain redundant information, the AI will confidently retrieve and generate well-phrased nonsense. The LLM can only be as smart as the library it has access to. Therefore, data quality, curation, and governance are not secondary concerns; they are foundation zero for any successful RAG project.
Challenge 2: The Retrieval Trap: When the Search Fails
The retrieval step is the heart of RAG, and it is also the most common point of failure. Even with advanced techniques, the retriever can fail in several critical ways, leading to poor-quality responses:
Missed Context: The most straightforward failure, where the retriever is unable to find the relevant document or passage that contains the answer to the user's query. This can happen due to poorly phrased queries or limitations in the embedding model's understanding.
Incomplete Context: The retriever finds the correct document but only pulls a fragment that lacks the necessary surrounding context to be properly understood. For example, retrieving a single row from a table without its headers.
Vague or Ambiguous Context: The retrieved information is too generic or high-level to be useful for answering a specific question. For instance, retrieving a general document about "privacy" when the user asked about "privacy considerations in web analytics".
Repetitive Context: The retriever pulls multiple, slightly different chunks of text that say essentially the same thing. This can confuse the generative model, leading to redundant and incoherent answers.
Challenge 3: The Missing Feedback Loop
A RAG system is not a static, "set it and forget it" application. It is a living system that must be continuously monitored and improved. Without robust feedback mechanisms, the system cannot learn from its mistakes. A successful implementation requires:
User Feedback: Simple mechanisms for users to rate the quality of responses (e.g., a thumbs up/down button) provide invaluable data on where the system is succeeding or failing.
Performance Monitoring: Developers must track key metrics like retrieval accuracy (precision and recall), response relevance, and latency to identify systemic issues and opportunities for tuning.
A Process for Improvement: There must be a clear process for using this feedback to refine the system, whether that involves improving data quality, fine-tuning embedding models, or adjusting chunking strategies.
Challenge 4: The Security-Usability Balance
In any enterprise setting, not all information is intended for all employees. A robust RAG system must be able to enforce access controls and data governance policies. This is a significant technical challenge. The system must be intelligent enough to know not only what information is relevant to a query but also whether the user asking the query is authorized to see it. This is especially critical in regulated industries like healthcare (HIPAA compliance) and finance, where data privacy and security are paramount. Building a system that is both highly useful and perfectly secure is a delicate balancing act.
Challenge 5: The "Needle in a Haystack" Problem
As knowledge bases grow from thousands to millions of documents, the challenge of finding the single most relevant piece of information, the "needle in a haystack" intensifies. This is related to the limitations of an LLM's context window. While context windows are getting larger, simply stuffing them with more and more retrieved documents can be counterproductive.
Ultimately, the most difficult challenges in building a world-class RAG system are often not machine learning problems. They are information architecture problems. Success hinges on meticulous data curation, a well-designed metadata strategy, intelligent document chunking, and robust access control—all core tenets of knowledge management. The ideal team for a RAG project, therefore, includes not just ML engineers, but also data stewards, domain experts, and even librarians who deeply understand the structure and meaning of the knowledge base. It is at this intersection of data science and information science that the most powerful and reliable RAG systems are born.
Closing Thoughts: The Future is Augmented
The journey from basic retrieval to advanced, multimodal, and multi-context systems mirrors our own intellectual development. We are teaching these systems not just to recite information, but to research, to reason, to synthesize, and to collaborate. The applications, as we have seen, are already reshaping industries, from accelerating life-saving medical diagnoses and securing financial systems to making the law more accessible and personalizing the way we learn.
The challenges in this journey are significant, but they are also instructive. They reveal that the future of AI is not solely about building bigger models, but about building smarter frameworks around those models. The competitive advantage will lie not in the generative engine itself, but in the quality of the proprietary data we can connect it to and the sophistication of the retrieval and augmentation pipeline that bridges the two.
The revolution, therefore, will not be memorized; it will be retrieved. The future of knowledge work is one where human expertise is not replaced by AI, but augmented by it, creating a powerful symbiosis where our ability to ask the right questions is amplified by an AI's ability to find the right answers.